
Introduction
In previous articles about ThreadLocal and ScopedValue, we detailed the roles of ThreadLocal and ScopedValue. Different multithreading environments create distinct local thread caching solutions. In actual project development, they function best when combined with multithreading environments.
Java’s concurrency programming is profound and ingenious, with structured concurrency and orchestrated concurrency being models and techniques within the field of concurrent programming. Structured concurrency primarily focuses on how to organize and manage concurrent activities, such as threads or tasks, more safely and clearly, making their lifecycles easier to understand and control. Orchestrated concurrency, on the other hand, focuses on how to describe and manage the order and dependencies of concurrent operations. This article mainly introduces orchestrated concurrency and the basics of reactive programming related to it.
Theoretical Understanding
Orchestrated Concurrency
A key challenge in concurrent programming is handling dependencies between operations, especially when multiple asynchronous operations need to be executed in a specific order. Orchestrated concurrency addresses this by providing a way to describe and control the order and dependencies of concurrent operations. In Java, CompletableFuture allows developers to declaratively describe the order and dependencies of operations, such as “perform when all operations are complete” or “perform when any operation is complete”. This makes orchestrating asynchronous operations more intuitive and easier to manage.
Structured Concurrency
In traditional concurrency models, after starting a new thread, task, or coroutine, these concurrent entities may run indefinitely unless explicitly stopped. This can make the program hard to understand and control, and may cause issues such as resource leaks and hard-to-capture errors. Structured concurrency emerged to make concurrent programming safer and simpler by providing stronger error handling and preventing resource leaks. Structured concurrency enforces a clear lifecycle for concurrent operations, where these lifecycles are nested within each other, making the management of concurrent operations more structured.
Problem Background
Focusing on CompletableFuture, we explore I/O-bound applications, with the most typical example being food delivery platforms. A food delivery platform is a classic B2C application that also includes a C2C business model. These platforms need to provide real-time messaging services for thousands of merchants, delivery personnel, and customers every day, which places immense pressure on the system as order volumes increase.
As the core part of the food delivery chain, the food delivery app’s merchant side provides key functions such as order reception and delivery, and the business demands on system throughput are growing. The API services on the merchant side are the traffic entry points, aggregating traffic for external merchant-facing functional interfaces and scheduling various downstream services to fetch and aggregate data. With the daily order volume reaching tens of millions, the drawbacks of synchronous loading methods have become apparent, and developers urgently need to adopt parallel loading to alleviate server pressure.
Synchronous vs. Asynchronous Models
A simple example can clarify the difference between synchronous and asynchronous processes. DNA requires unwinding before synthesizing a base chain during semi-conservative replication, which is a synchronous process because polymerase always has to wait for helicase or topoisomerase to finish unwinding before continuing; the translation of mRNA can have multiple rRNAs attaching to the base chain simultaneously to synthesize multiple proteins, which is an asynchronous process because each rRNA does not need to wait for the previous one to finish.
Synchronous Model
The most common method of retrieving data from services is through synchronous calls. For example, in e-commerce, as shown in the sequence diagram below:
Customer ->> Website: Browse products (T1) Website ->> Database: Query product information (T2) Database -->> Website: Return product information (T3) Website -->> Customer: Display product (T4)
Customer ->> Website: Add to cart (T5) Website ->> Database: Update cart (T6) Database -->> Website: Return updated cart (T7) Website -->> Customer: Display updated cart (T8)In synchronous calling scenarios, interface latency and performance issues arise. With network fluctuations, CPU throttling, and other uncontrollable factors, the response time . To reduce response time, a thread pool is used to retrieve data in parallel:
Customer ->> Thread1: Request product 1 details Thread1 ->> Database: Fetch product 1 details Customer ->> Thread2: Request product 2 details Thread2 ->> Database: Fetch product 2 details Database -->> Thread1: Return product 1 details Thread1 -->> Customer: Display product 1 Database -->> Thread2: Return product 2 details Thread2 -->> Customer: Display product 2
Customer ->> Thread3: Add product to cart Thread3 ->> Database: Update cart Database -->> Thread3: Cart updated Thread3 -->> Customer: Display updated cartIn this example, the user can request multiple product details simultaneously, and each request is processed by a different thread from the thread pool. Therefore, the user does not have to wait for the details of product 1 to be returned before requesting the details of product 2.
Parallel tasks can improve performance when processing a large number of concurrent requests, but multithreading can cause system resource wastage, and the system’s throughput can easily reach a bottleneck:
- CPU resources are heavily wasted on blocking waits, leading to low CPU resource utilization. Before Java 8, asynchronous operations were typically achieved through callbacks, where one function (or method) was passed as a parameter to another function (or method), and the callback was invoked when the operation finished or data became available. From Java 8 onwards,
CompletableFuturewas introduced, which implements theFutureinterface and represents the result of an asynchronous computation. Unlike traditionalFuture,CompletableFutureprovides richer APIs to handle asynchronous operations, including chaining, composition, and exception handling, alleviating the “callback hell” issue. Java 9 introduced the Reactive Streams API specification, providing a standard model for asynchronous, event-driven data processing, with a back-pressure mechanism allowing consumers to control the rate at which data is produced to avoid memory overflow when processing large data. - To increase concurrency, additional thread pools are introduced, and with the increase in the number of threads scheduled by the CPU, resource contention worsens. Valuable CPU resources are consumed in CPU context switching, and threads themselves also occupy system resources and cannot be infinitely increased. Starting from Java 19, the introduction of the structured concurrency model allows developers to organize and manage concurrent tasks using a simpler concurrency programming model, thus avoiding unnecessary thread creation and resource waste.
Asynchronous Model
From callbacks to CompletableFuture, and then to Reactive Streams, this represents an evolution in Java’s asynchronous programming model. Each model tries to minimize blocking, improve the program’s responsiveness, and increase the readability and maintainability of the code. Before Java 8, there were primarily two asynchronous models to reduce thread pool scheduling overhead and blocking time:
- Using RPC NIO asynchronous calls to reduce the number of threads, thus lowering the scheduling (context-switching) overhead.
- Introducing
CompletableFutureto perform concurrent orchestration of business processes, reducing blocking between dependencies.
As Java versions evolved, Java 9 introduced a new asynchronous programming model:
- Reactive Streams, which provide a standard for handling data streams, especially suitable for processing large data streams or tasks that require long waiting times.
We can intuitively see the evolution of various asynchronous models through the following table:
| Future | CompletableFuture | Reactive Stream | RxJava | Reactor | |
|---|---|---|---|---|---|
| Composable (Composable) | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
| Asynchronous (Non-blocking) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Operator fusion | ❌ | ❌ | ❌ | ✔️ | ✔️ |
| Lazy (Deferred execution) | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| Backpressure (Back-pressure mechanism) | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
| Functional (Functional programming) | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
- Composable: It allows multiple dependent operations to be orchestrated in various ways. For example,
CompletableFutureprovides methods likethenCompose()andthenCombine(), which support the “composable” feature. We can compare it to thethen()orcatch()chaining in JavaScript ES6’s Promise structure (Java 8 was released in 2014, while ES6 came out in 2015). - Asynchronous Non-blocking: Asynchronous means that once an operation starts, other operations can continue without waiting for the current one to finish. Non-blocking means that when a request (e.g., an I/O request) cannot be fulfilled immediately, the executing thread will not be suspended; instead, it can continue executing other tasks. This model is more efficient in utilizing system resources and improves system concurrency and throughput.
- Operator Fusion: Combining multiple operations into one to improve efficiency. This can reduce unnecessary intermediate results, save memory, and decrease task scheduling overhead, thereby improving overall processing performance. This is more common in Reactive Streams. A stream operation like
list.stream().map().filter().toList()can be intuitively understood here. - Lazy Execution: The core idea of lazy execution is functional programming, where operations are defined and executed only when needed, such as calling
accept()at the end. This pattern postpones computation until the result is required, often achieved by returning a function (or “lazy-loaded” function). Many non-functional programming languages and environments also provide mechanisms for lazy execution, likeCompletableFuturein Java, which only triggers operations when there are subscribers, orPromisein JavaScript, which executesthen()after an operation completes. - Back-pressure: This is a critical concept in stream processing systems, allowing the receiver to control the data sending rate of the sender, preventing overload. In real back-pressure systems, the receiver adjusts the production speed of the sender according to its processing capacity. This leads to better flow control, and in reactive programming models like Reactor or RxJava, back-pressure is built-in and helps control flow. This will be introduced later in Reactive Streams.
- Functional Programming: Some people mistakenly equate functional programming with anonymous function expressions, which are related but distinct concepts. Functional programming is a programming paradigm, while anonymous function expressions are a technique used within it. These expressions are common in functional programming but can also be used in non-functional contexts.
Orchestrating Concurrency
We generally agree with the viewpoint that “developers who only know how to use lock(), unlock(), wait(), and notify() to solve multithreading problems lack fundamental skills.” If developers only know how to use these synchronization mechanisms but don’t understand the underlying principles, they may struggle with more complex concurrency issues. Orchestrating concurrency not only tests a programmer’s understanding of task dependencies when dealing with multithreading or asynchronous tasks, but also their grasp of concurrency and asynchronous concepts.
Concurrency orchestration (CompletableFuture) began with Java 8 and was further enhanced in Java 9. While CompletableFuture implements the Future interface, it offers a more elegant code structure and reduces the complexity of asynchronous task orchestration compared to FutureTask.
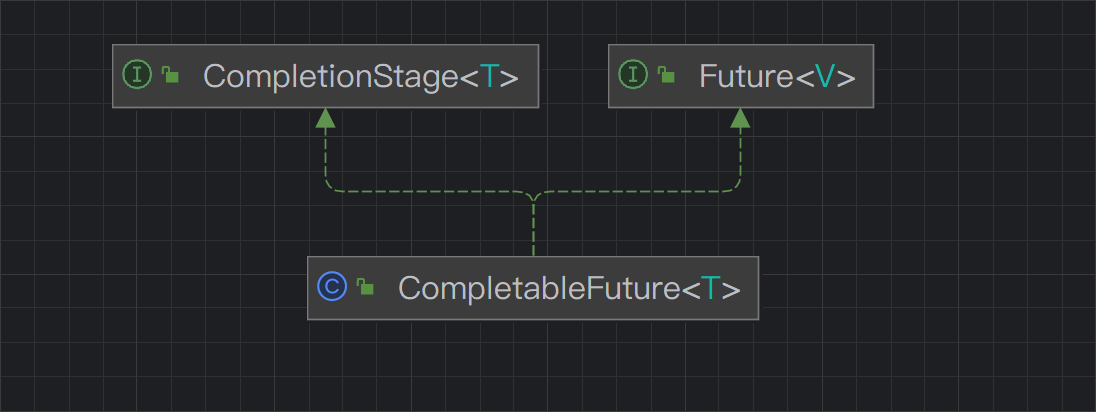
Future represents the result of an asynchronous computation, and CompletionStage represents a step in the asynchronous execution process (Stage). This step may trigger another CompletionStage, and as the current step completes, it can trigger a series of other CompletionStage executions. We can then orchestrate these steps in various ways based on actual business needs. The CompletionStage interface defines this capability, and we can combine and orchestrate these steps using functional programming methods like thenApply, thenCompose, and others.
Case Introduction
We can break down the dining process in a cafeteria into several steps:
- Upon entering the cafeteria, you first decide what to eat, choosing an appropriate counter (e.g., rice, noodles, or spicy hot pot).
- After choosing the noodle counter, the next step is to queue up and tell the server you want a bowl of vegetable noodles.
- The server informs the chef to start preparing the vegetable noodles for you.
- While waiting, you pick a good spot and read articles from Dioxide_CN to pass the time.
- The chef hands the prepared vegetable noodles to the server, who notifies you to pick them up at the counter, allowing you to start enjoying your meal.
Before Java 8, we would use FutureTask to implement this task:
public static void main(String[] args) {
print("I entered the stall and chose vegetable noodles");
FutureTask<String> task1 = new FutureTask<>(() -> {
print("The waiter told the chef to prepare the vegetable noodles");
sleep(200);
return "Notice has been issued";
});
new Thread(task1).start();
try {
task1.get(); // Wait for task1 to complete
FutureTask<String> task2 = new FutureTask<>(() -> {
print("Chef making vegetable noodles");
sleep(300);
return "Vegetable noodles";
});
new Thread(task2).start();
task2.get(); // Wait for task2 to complete
FutureTask<String> task3 = new FutureTask<>(() -> {
print("The waiter notifies the customer to pick up the meal");
sleep(100);
return "Completed notification and production";
});
new Thread(task3).start();
print(task3.get() + ", I started eating."); // Wait for task3 to complete and print the result
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
print("I read the article while waiting for my meal");
}Although FutureTask is feasible and outputs the expected results, the code is not beautiful and stable, and is not conducive to later developers to maintain. At the same time, it triggers the callback hell problem that developers hate. Let’s take a look at the improved code using CompletableFuture:
public static void main(String[] args) {
print("I entered the stall and chose vegetable noodles");
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
print("The waiter told the chef to prepare the vegetable noodles");
sleep(200);
return "Notice has been issued";
}).thenCombine(CompletableFuture.supplyAsync(() -> {
print("Chef making vegetable noodles");
sleep(300);
return "Vegetable noodles";
}), (notification, result) -> {
print("The waiter notifies the customer to pick up the meal");
sleep(100);
return "Chef " + notification + " finish cooking " + result;
});
print("I read the article while waiting for my meal");
print(cf1.join() + ", I started eating.");
}We can notice that a ForkJoinPool thread pool is opened during the execution of CompletableFuture.supplyAsync().
Multiple Dependencies
In real development scenarios, it is unlikely to encounter such a simple usage as in the above case. Using CompletableFuture is a process of constructing a complete dependency tree. The completion of one CompletableFuture triggers the execution of another or a series of CompletableFuture that depend on it, which is somewhat like a chain reaction. Depending on the number of dependencies of a CompletableFuture, they can be categorized as zero dependency, unary dependency, binary dependency, and multiple dependencies.
Zero Dependency
Zero dependency is the most basic dependency in CompletableFuture. Here, we directly provide a case, with no need for further explanation:
public class CompletableFutureExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int a = 2, b = 3;
// Asynchronous Task 1: Get the sum of two numbers
CompletableFuture<Integer> futureSum = CompletableFuture.supplyAsync(() -> a + b);
// Asynchronous Task 2: Get the product of two numbers
CompletableFuture<Integer> futureProduct = CompletableFuture.supplyAsync(() -> a * b);
// Execute two asynchronous tasks and output the results
System.out.println("The sum is: " + futureSum.get()); // Block until the asynchronous task is completed
System.out.println("The product is: " + futureProduct.get()); // Block until the asynchronous task is completed
}
}In this example, two asynchronous tasks are created to calculate the sum and the product of two numbers, respectively. Since these two tasks have no dependencies on each other, i.e., they have zero dependencies, they can be executed in parallel. We wait for their execution results by calling the CompletableFuture.get() method.
Unary Dependency
Referring back to the earlier example, the unary dependency is relatively easy to understand. This type of dependency on a single CompletableFuture can be implemented using methods such as thenApply(), thenAccept(), and thenCompose().
Binary Dependency
Expanding on the previous example, let’s assume that the waiter now needs to be responsible for both reheating the food and serving it. In this case, the final customer meal depends on both the chef serving the food and the waiter serving it, forming a binary dependency. A binary dependency can be achieved using callbacks like thenCombine(), which is also demonstrated in the example.
Multiple Dependencies
With an understanding of unary and binary dependencies, multiple dependencies become easier to comprehend. That is, a task depends on the results of several tasks before it. Multiple dependencies can be implemented using methods like allOf or anyOf. The difference is that allOf is used when all dependencies need to be completed (complete dependency), while anyOf is used when any one of the dependencies being completed is sufficient (partial dependency).
CompletableFuture<Void> cf6 = CompletableFuture.allOf(cf3, cf4, cf5);
CompletableFuture<String> result = cf6.thenApply(v -> {
// The join here will not block, because the function passed to thenApply
// will not be executed until CF3, CF4, and CF5 are all completed.
result3 = cf3.join();
result4 = cf4.join();
result5 = cf5.join();
// Assemble the final result according to result3, result4, and result5.
return "result";
});More Complex Dependency Models
In actual development, we rarely encounter simple point-to-point multiple dependency models. Instead, we often deal with complex dependency models formed by various unary, binary, and multiple dependencies.
When handling these more complex dependency models, CompletableFuture shows a significant advantage over FutureTask. This is why more developers tend to use CompletableFuture for orchestrating concurrency.
Underlying Principles of CompletableFuture
In the CompletableFuture class, there are two variables marked as volatile: Object result and Completion stack:
result: This variable stores the result of theCompletableFuture. Its type isObjectbecauseCompletableFutureis a generic class and can be used for any type of calculation result. When theCompletableFutureis completed, the result is stored in this variable.stack: This variable stores all the dependent tasks and is the topmost element of the stack. When aCompletableFutureobject is completed (i.e., its result is available), all tasks that depend on thisCompletableFuture(such as those registered through methods likethenApply,thenAccept,thenCompose) need to be executed. TheCompletion stackstores these pending tasks.
Completion
Completion uses a data structure called Treiber stack to store tasks. This structure is similar to a stack and follows the “Last In, First Out (LIFO)” rule. Therefore, the last registered task is executed first. This structure ensures more efficient task management in a single-threaded environment.
UniCompletioninherits fromCompletionand serves as the base class for unary dependencies. For example, the implementation classUniApplyofthenApplyinherits fromUniCompletion.BiCompletioninherits fromUniCompletionand serves as the base class for binary dependencies, as well as the base class for multiple dependencies. For example, the implementation classBiRelayofthenCombineinherits fromBiCompletion.
The Treiber stack is a lock-free concurrent stack data structure proposed by R. Kent Treiber that provides better performance in high-concurrency environments. The Treiber stack uses a series of CAS atomic operations via VarHandle STACK to achieve push and pop operations, which is one of the key features that enable it to be a lock-free concurrent stack.
VarHandle
VarHandle is a new low-level mechanism introduced in Java 9, primarily designed to provide a safer and more user-friendly way to support various complex atomic operations than sun.misc.Unsafe. VarHandle provides a standardized mechanism for accessing various data types, whether they are static, instance, or array types. It supports many powerful operations, including atomic updates to individual variables, ordered or volatile access to variables, ordered or volatile access to array elements, and compare-and-set (CAS) operations for fields and array elements.
@SuppressWarnings("serial")
abstract static class Completion extends ForkJoinTask<Void>
implements Runnable, CompletableFuture.AsynchronousCompletionTask {
volatile CompletableFuture.Completion next; // Treiber stack link
/**
* Performs completion action if triggered, returning a
* dependent that may need propagation, if one exists.
*
* @param mode SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture<?> tryFire(int mode);
/** Returns true if possibly still triggerable. Used by cleanStack. */
abstract boolean isLive();
public final void run() { tryFire(ASYNC); }
public final boolean exec() { tryFire(ASYNC); return false; }
public final Void getRawResult() { return null; }
public final void setRawResult(Void v) {}
}- Completion Stack in
CompletableFutureexhibits characteristics of a linked list. It is a stack implemented as a linked list, whereCompletionobjects are linked together via thenextfield. However, this does not contradict the stack’s definition. When we say Completion Stack is a stack, we typically mean that its operations follow the LIFO (Last In, First Out) principle. - Lock-Free Concurrent Stack describes the concurrency behavior of the Completion Stack. Lock-Free means that even in a multi-threaded environment, there is no need to use traditional mutex locks to protect data. Instead, atomic operations are used to ensure data consistency and thread safety. This approach reduces thread blocking and improves the system’s concurrency performance.
In CompletableFuture, VarHandle is used to implement atomic operations on the Completion linked list. The Completion linked list is a data structure in CompletableFuture used to store dependent tasks, which need to be executed after the CompletableFuture completes. VarHandle provides an efficient and thread-safe way to manipulate this linked list.
By using VarHandle, CompletableFuture ensures that even in a concurrent environment, adding, removing, and executing dependent tasks can proceed correctly. This is achieved through atomic operations and fine-grained control over memory access, without relying on heavyweight synchronization mechanisms such as synchronized blocks or Lock objects.
Handling Dependencies
Whether using supplyAsync() or runAsync(), they ultimately execute a constructed AsyncSupply or AsyncRun object through a specified or built-in Executor.
executor.execute(new AsyncSupply<U>(completableFuture, supplier)); // asyncSupplyStage Line 1778
executor.execute(new AsyncRun(completableFuture, runnable)); // asyncRunStage Line 1815Let’s focus on these two inner classes, both of which inherit from ForkJoinTask<Void> and implement the Runnable and AsynchronousCompletionTask interfaces. The overridden run() methods are quite similar. The difference lies in the fact that the Runnable type cannot obtain a return value, so in AsyncRun, the completeNull() method is used, while in AsyncSupply, which can return a value, the completeValue() method is used. The result is then stored in the VarHandle RESULT through a CAS operation.
These two methods are similar to the observer pattern, where asynchronous calls notify observers in different threads. Further down, you will see they both call the postComplete() method:
final void postComplete() {
CompletableFuture<?> f = this; CompletableFuture.Completion h;
// This loop will continue until f.stack is empty, that is,
// there are no more dependencies to process.
while ((h = f.stack) != null ||
(f != this && (h = (f = this).stack) != null)) {
CompletableFuture<?> d; CompletableFuture.Completion t;
// Set f.stack from h to h.next. If successful,
// h will be removed from the stack and
// t will become the new top element of the stack.
if (STACK.compareAndSet(f, h, t = h.next)) {
// If t is not null, push the current h into this.stack
// and continue the next loop
if (t != null) {
if (f != this) {
pushStack(h);
continue;
}
NEXT.compareAndSet(h, t, null); // try to detach
}
// Execute the dependent action represented by h
// and assign the execution result to d
f = (d = h.tryFire(NESTED)) == null ? this : d;
}
}
}This method is easy to understand. It uses a while loop to process all the dependencies in the current CompletableFuture object, ensuring that once this CompletableFuture is completed, all callbacks dependent on it are executed correctly. Each iteration of the loop removes the dependency at the top of the stack until all dependencies are handled. These operations are implemented through atomic operations using VarHandle.
Binding Dependencies
Now that we have learned how CompletableFuture handles dependent tasks, let’s look at how dependencies are added. In CompletableFuture, methods like thenCombine(), thenCombineAsync(), thenCompose(), and thenComposeAsync() are used to bind dependencies to a previous CompletableFuture. Even though their behaviors and purposes vary, we will discuss these differences later. For now, let’s analyze the general flow of these methods:
- Compose methods internally call
uniComposeStageand then invoke theunipushmethod with aUniComposeobject. - Combine methods internally call
biApplyStageand then invoke thebipushmethod with aBiApplyobject.
Undoubtedly, both types of methods complete the dependency binding in the push phase. This binding process essentially establishes a dependency relationship and pushes it onto the Treiber stack. Let’s track these two types of methods separately to see how they are implemented:
Compose: Both
thenComposeandthenComposeAsyncmethods are implemented through theuniComposeStagemethod. We can understand this process better by going through the code with comments:private <V> CompletableFuture<V> uniComposeStage( Executor e, Function<? super T, ? extends CompletionStage<V>> f) { // If f is null, throw a NullPointerException if (f == null) throw new NullPointerException(); // Create a new CompletableFuture instance 'd', which is an incomplete CompletableFuture CompletableFuture<V> d = newIncompleteFuture(); Object r, s; Throwable x; // Check the result of the current CompletableFuture if ((r = result) == null) // If result is null, it means the current CompletableFuture is not completed yet // So create a new UniCompose instance and add it to the dependency chain, waiting for the current CompletableFuture to complete unipush(new CompletableFuture.UniCompose<T,V>(e, d, this, f)); else { // If result is not null, the current CompletableFuture is completed, proceed to execute f // If result is an instance of AltResult, it means the result of the current CompletableFuture is an exception // In this case, we set this exception in the new CompletableFuture 'd' and return 'd' if (r instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)r).ex) != null) { d.result = encodeThrowable(x, r); return d; } r = null; // Reset r to null and let GC handle it } // If result is not an instance of AltResult, it means the current CompletableFuture completed with a normal value // Now proceed to call f to process this value. try { // If the passed Executor e is not null, it means the function f needs to be executed asynchronously in the specified Executor // Create a new UniCompose instance and submit it to Executor e for execution // This is the key difference between whether the method is Async or not if (e != null) e.execute(new CompletableFuture.UniCompose<T,V>(null, d, this, f)); else { // Otherwise, execute function f synchronously @SuppressWarnings("unchecked") T t = (T) r; // Call function f and get the returned CompletionStage, then convert it to CompletableFuture CompletableFuture<V> g = f.apply(t).toCompletableFuture(); // Check the result of the new CompletableFuture 's' // If s is not null, it means the CompletableFuture returned by function f is already completed // In this case, set this result in the new CompletableFuture 'd' if ((s = g.result) != null) d.result = encodeRelay(s); else // If s is null, it means the CompletableFuture returned by function f is not completed yet // We need to create a new UniRelay instance and add it to the dependency chain // Waiting for the CompletableFuture returned by function f to complete g.unipush(new CompletableFuture.UniRelay<V,V>(d, g)); } } catch (Throwable ex) { d.result = encodeThrowable(ex); } } return d; }The purpose of this method is to implement the
thenComposeandthenComposeAsyncmethods, which means that after the currentCompletableFutureis completed, a functionfthat returns aCompletionStageis executed, and a newCompletableFutureis returned. The result of this newCompletableFutureis the result of theCompletionStagereturned by functionf.It is evident that the
unipushmethod is responsible for handling new instances of theCompletiontype and pushing them onto the Treiber stack.final void unipush(CompletableFuture.Completion c) { // Check if the passed Completion object c is null if (c != null) { // Call the tryPushStack(c) method in a loop, // trying to push c into the stack until it succeeds // This is a very classic cyclic spin operation, // which can be compared to the cyclic spin lock method. while (!tryPushStack(c)) { if (result != null) { // Set the next field of Completion c to null // This is to disconnect the link between c and its next // Prevent subsequent operations from affecting Completion objects other than c NEXT.set(c, null); break; } } // After the stack is pushed, if result is not empty, execute c immediately if (result != null) c.tryFire(SYNC); } }The whole stacking process is not difficult. It is to pass the
applyresult ofFunctioninthenComposeorthenComposeAsyncas a newCompletiontounipush.unipushpushes thisCompletionto the top of thestack. If the currentCompletionFuturehas produced a result, then the top element of the stack is immediately notified to perform the operation.Combine, the
thenCombineandthenCombineAsyncmethods are both implemented through thebiApplyStagemethod. Although it is different from Compose, the concept is basically the same. We still focus on the methodbiApply()that binds dependencies:final <R,S> boolean biApply(Object r, Object s, BiFunction<? super R,? super S,? extends T> f, CompletableFuture.BiApply<R,S,T> c) { Throwable x; // First, check if the result already exists. If the result already exists, return true directly // because we do not want to perform operations on an already completed CompletableFuture tryComplete: if (result == null) { // Check the two results r and s. If either of these results is of type CompletableFuture.AltResult // then set the exception as the final result using the completeThrowable method and skip the following steps if (r instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)r).ex) != null) { completeThrowable(x, r); break tryComplete; } r = null; } if (s instanceof CompletableFuture.AltResult) { if ((x = ((CompletableFuture.AltResult)s).ex) != null) { completeThrowable(x, s); break tryComplete; } s = null; } // If both results are valid, attempt to apply them to the BiFunction f try { // The claim method is used here, which tries to change the state of the Completion // from not decided (NEW) to decided (COMPLETING) if (c != null && !c.claim()) return false; // If the change fails, return false directly // If the change succeeds, attempt to apply the BiFunction // and use the completeValue method to complete the CompletableFuture @SuppressWarnings("unchecked") R rr = (R) r; @SuppressWarnings("unchecked") S ss = (S) s; completeValue(f.apply(rr, ss)); } catch (Throwable ex) { completeThrowable(ex); } } return true; }biApplydoes not explicitly perform dependency binding operations, and it does not involve operations with the lock-free concurrent stack. It also has some differences fromCompose:uniComposeStageis used forthenComposeorthenComposeAsyncoperations, which are executed when aCompletableFutureis completed. On the other hand,biApplyis used forthenCombineorthenCombineAsyncoperations, which are executed when the results of twoCompletableFutureinstances are both completed.- The
unipushmethod mainly pushes aCompletiononto thestack, and if theCompletableFutureis already completed, it attempts to execute theCompletion; whereas thebiApplymethod attempts to apply the two results to aBiFunctionand complete theCompletableFuture. These two methods differ in their execution strategies and result handling. - The
unipushmethod handles a singleCompletionobject, whereas thebiApplymethod handles two results and aBiFunction.
Let’s look at the differences between Combine and Compose methods:
- The
thenComposemethod is used to handle nestedCompletableFutureinstances. It accepts a function as a parameter, where the input is the result of the previousCompletableFuture, and the output is a newCompletableFuture.thenComposewaits until both the outerCompletableFutureand the innerCompletableFutureare completed.CompletableFuture.supplyAsync(() -> "Hello") .thenCompose(s -> CompletableFuture.supplyAsync(() -> s + " World")) .thenAccept(System.out::println); // "Hello World" - The
thenCombinemethod is used to combine the results of two independentCompletableFutureinstances. It accepts two parameters: one is anotherCompletableFuture, and the other is a function that takes the results of bothCompletableFutureinstances as inputs and returns the final result.CompletableFuture.supplyAsync(() -> "Hello") .thenCombine(CompletableFuture.supplyAsync(() -> " World"), (s1, s2) -> s1 + s2) .thenAccept(System.out::println); // "Hello World"
Timeout and Blocking
After extensively discussing CompletableFuture, we have understood its multivariable dependencies, concurrent orchestration, how to handle dependent CompletableFuture instances, and how to bind dependencies. Apart from exception handling and delayed execution, the last remaining topic is timeout handling and thread blocking. Exception handling and delayed execution methods and their underlying implementations are not complex, so here we focus on further analysis of timeouts and blocking.
Timeout
Timeout handling was introduced in CompletableFuture in Java 9, including the orTimeout and completeOnTimeout methods:
CompletableFuture<T> orTimeout(long timeout, TimeUnit unit): If the originalCompletableFuturecompletes within the timeout, the returnedCompletableFuturewill have the same result as the original. If the originalCompletableFuturedoes not complete within the timeout, the returnedCompletableFuturewill complete with aTimeoutException.CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit): This method returns a newCompletableFuture. If the originalCompletableFuturecompletes within the specified timeout, the returnedCompletableFuturewill have the same result as the original. If the originalCompletableFuturedoes not complete within the timeout, the returnedCompletableFuturewill complete with the given valuevalue.
The second method is more elegant, and we can compare it to the Optional.orElse method. Both methods return a new CompletableFuture and do not modify the original CompletableFuture. This is consistent with other methods of CompletableFuture, ensuring its immutability.
However, these timeout methods do not stop the original CompletableFuture from continuing its execution. If the task is not properly interrupted, it may continue executing after the timeout. Therefore, it is important to ensure that the task code can correctly respond to interruptions and handle disaster recovery to stop execution immediately after the timeout.
In terms of timeout handling, readers may consider the following questions:
Q: What harm can occur to a concurrent program if no timeout or timeout handling strategy is set? A: This question should be considered from both synchronous and asynchronous perspectives:
- Synchronous tasks: For synchronous tasks, if an operation cannot complete within the expected time due to various reasons (e.g., network fluctuation, deadlock), it will block the main thread, affecting the execution of subsequent tasks. This can cause the program to hang and be unable to process new requests.
- Asynchronous tasks: For asynchronous tasks, if an operation cannot complete for an extended period due to various reasons (e.g., infinite loops, resource contention), the asynchronous task may occupy thread resources for a long time, leading to a lack of threads in the thread pool and affecting the execution of other tasks. Additionally, since the result of a
CompletableFutureis typically used to trigger further computation or operations, if aCompletableFuturedoes not complete within the expected time, it may cause delays or hang in the entire computation process.
Q: Since there was no timeout-related code before Java 9, how could these methods be implemented? A: Even before Java 9, when
CompletableFuturedid not provide timeout strategies, it was still possible to implement them through workarounds:- ScheduledExecutorService: Use
ScheduledExecutorServiceto complete aCompletableFutureafter a specific delay. You can use thecompletemethod ofCompletableFutureto set a default result or exception after a timeout. The drawback of this approach is that the timeout does not interrupt the original task, so if the task is not properly handling interruptions, it may continue executing after the timeout.public class CompletableFutureWithTimeout { public static void main(String[] args) throws ExecutionException, InterruptedException { // Create a ScheduledExecutorService for executing timeout tasks ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); // Create a CompletableFuture that will be executed CompletableFuture<String> completableFuture = new CompletableFuture<>(); // Create a Runnable task to complete the CompletableFuture after a timeout Runnable timeoutTask = () -> { completableFuture.completeExceptionally(new TimeoutException("Timeout after 5 seconds")); }; // Schedule the timeout task to execute after 5 seconds ScheduledFuture<?> timeoutFuture = scheduler.schedule(timeoutTask, 5, TimeUnit.SECONDS); // Monitor the completion of the CompletableFuture. If the CompletableFuture completes before the timeout, cancel the timeout task completableFuture.whenComplete((result, ex) -> { if (ex == null) { timeoutFuture.cancel(false); } else { System.out.println("CompletableFuture completed exceptionally: " + ex.getMessage()); } }); // Simulate a long-running task that takes 10 seconds to complete CompletableFuture.runAsync(() -> { try { Thread.sleep(10000); } catch (InterruptedException ignored) {} completableFuture.complete("Task completed"); }); // Get the result of the CompletableFuture. If the CompletableFuture times out, the get method will throw an ExecutionException try { String result = completableFuture.get(); System.out.println("Result: " + result); } catch (ExecutionException e) { if (e.getCause() instanceof TimeoutException) { System.out.println("Task timed out"); } } // Finally, remember to shut down the ScheduledExecutorService scheduler.shutdown(); } } - Future.get: For
Future, theget(long timeout, TimeUnit unit)method can be used to wait for theFutureto complete within the specified timeout. If the timeout is exceeded, thegetmethod will throw aTimeoutException. However, this method only works for blocking waits and is not suitable for asynchronous programming models.
- ScheduledExecutorService: Use
Blocking
There are several situations where synchronous blocking is used to handle tasks:
- The amount of data to be processed is small, and the task execution time is short.
- There is a strict execution order between tasks, and easier management and control are needed.
- The project’s requirements and business logic are relatively simple.
- Low frequency of data interaction and IO non-intensive applications.
- System resources (such as CPU, memory) are tight, and using concurrency could exhaust system resources.
In an asynchronous concurrent environment, we need to arrange thread resources reasonably, and the premise of proper arrangement is to clearly understand which thread a task is assigned to:
- If the dependent operation is already completed when registered, the thread of the preceding dependent task will execute it.
- If the dependent operation is not yet completed when registered, the thread of the callback task will execute it.
In the previous analysis of dependency handling and binding dependencies, we mentioned variant methods of the same type of Async methods. These methods all have an overloaded version that requires passing in an Executor executor. In development, it is more recommended to use asynchronous methods that require passing in a thread pool. If no thread pool is provided, the common thread pool CommonPool in ForkJoinPool will be used. As a result, all asynchronous callback tasks will be mounted to this common thread pool, and both core and non-core business tasks will compete for the threads in the same pool, which can easily cause system bottlenecks. Manually passing thread pool parameters makes it easier to adjust parameters, and allows different business tasks to be allocated to different thread pools for resource isolation, reducing interference between different business tasks. Circular references in thread pools can lead to deadlock issues, as shown in the example below:
public Object doGet() {
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
// do sth
return CompletableFuture.supplyAsync(() -> {
System.out.println("child");
return "child";
}, threadPool1).join(); // sub task
}, threadPool1);
return cf1.join();
}The cause of deadlock is that both the main task and the subtask share the same thread pool, and the main task depends on the result of the subtask. When the number of concurrent main tasks exceeds the size of the thread pool, each main task will block waiting for the result of its subtask, but the subtask cannot be executed because all the threads in the thread pool are occupied by blocked main tasks, resulting in a deadlock. Similarly, it is not only tasks with parent-child relationships that can cause deadlocks. Deadlocks may occur whenever more than two tasks that form dependencies simultaneously use the same thread pool:
public Object doGet() {
ExecutorService threadPool = Executors.newFixedThreadPool(1);
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "cf1";
}, threadPool);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {
try {
return cf1.get(); // Waiting for the result of cf1 here
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return null;
}, threadPool); // cf1 and cf2 are in the same thread pool
return cf2.join();
}CompletableFuture plays a crucial role in today’s concurrent programming. Introduced in Java 8, it is a powerful concurrency programming tool that brings a new programming paradigm — an asynchronous programming model based on callbacks and chained calls. When facing complex concurrent scenarios such as network requests, database access, and IO-intensive tasks, CompletableFuture allows developers to easily build efficient and robust concurrent applications with its powerful functionality and flexible API. This has greatly contributed to Java’s widespread adoption in fields such as server-side programming and big data processing, and it undoubtedly occupies a central position in today’s concurrent programming.
The Remaining Value of FutureTask
Both FutureTask and CompletableFuture are concurrency utility classes in Java, and both implement the Future interface, which can be used to represent the result of an asynchronous computation. Although CompletableFuture provides richer functionality and a better programming model, FutureTask still has its value and applicable scenarios. Both FutureTask and CompletableFuture have their own advantages and disadvantages and are suitable for different situations. The choice between the two should depend on specific needs and the environment:
- Compatibility:
CompletableFuturewas introduced in Java 8, whileFutureTaskwas introduced in Java 5. Therefore, for older Java code and libraries or projects that still need to support Java 7 and earlier versions,FutureTaskis a better choice. - Simplicity: Although
CompletableFutureoffers more powerful features, this also makes its usage and understanding slightly more complex. For simpler concurrency requirements, usingFutureTaskmay be simpler and more intuitive. - Task Cancellation:
FutureTaskprovides acancelmethod that can be used to cancel a task’s execution. WhileCompletableFuturealso offers similar functionality,FutureTask’s cancellation feature is more direct and simple. - RunnableFuture:
FutureTaskimplements theRunnableFutureinterface, which allows it to be directly executed by a thread, whereasCompletableFuturedoes not have this functionality. This makesFutureTaskoffer better performance and flexibility in certain situations.
Reactive Streams
Case Introduction
Reactive Streams is an implementation of asynchronous streaming programming. Reactive Streams is based on an asynchronous publish-subscribe model, characterized by non-blocking “backpressure” data processing. Reactive Streams is a more powerful asynchronous programming specification, and from this specification, powerful reactive libraries like RxJava and Reactor have been derived. These libraries provide higher-level APIs, allowing developers to more easily handle streaming data, including creating, transforming, combining, and consuming streams.
We will once again use the example of queuing for a meal, demonstrating a simple reactive stream program using Reactor.
public static void main(String[] args) {
print("I entered the stall and chose vegetable noodles");
Mono<String> notice = Mono.fromCallable(() -> {
print("The waiter told the chef to prepare the vegetable noodles");
sleep(200);
return "Notice has been issued";
}).subscribeOn(Schedulers.boundedElastic());
Mono<String> cook = Mono.fromCallable(() -> {
print("Chef making vegetable noodles");
sleep(300);
return "Vegetable noodles";
}).subscribeOn(Schedulers.boundedElastic());
print("I read the article while waiting for my meal");
Mono.zip(notice, cook)
.map(tuple -> {
print("The waiter notifies the customer to pick up the meal");
sleep(100);
return "Chef " + tuple.getT1() + " finished cooking " + tuple.getT2();
})
.doOnNext(result -> {
print(result + ", I started eating.");
})
.block();
}Although this reactive stream also meets our requirements, it can be observed that its runtime always takes about 100 milliseconds longer than CompletableFuture. This phenomenon is mainly due to the operating system’s thread scheduling strategy or the JVM’s workload.
Reactive Streams Specification
Reactive Streams is a reactive stream specification jointly proposed by Netflix, Pivotal (now VMware), Lightbend (formerly Typesafe), and several other companies. It was not proposed by the Java language or Oracle. This specification defines a set of interfaces (
Publisher,Subscriber,Subscription, andProcessor), as well as a set of related behaviors and protocols, to support asynchronous, backpressure-aware stream processing. Thejava.util.concurrent.Flowclass and its four nested interfaces introduced in Java 9 are an implementation of the Reactive Streams specification. Its goal is to provide a standard and low-level reactive programming API, allowing various Java-based libraries and frameworks to build higher-level APIs and functionalities on top of it. In addition, frameworks like Reactor, RxJava, and Akka Streams are also implemented based on the Reactive Streams specification. They provide a large number of operators and convenient APIs to support various complex stream processing and transformations. Therefore, we need to be clear that these frameworks are developed based on the Reactive Streams specification, not Java 9’s Flow API, so they do not depend on Java 9 and can run on earlier versions of Java. For example, Reactor 3 and RxJava 2 can run on Java 8.
The interfaces in this specification can be found in the reactive-streams dependency or Java 9’s Flow class. In this chapter, we will primarily use the Reactor framework for illustration.
implementation 'org.reactivestreams:reactive-streams:1.0.4'<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.4</version>
</dependency>Publish-Subscribe Pattern
The Publish-Subscribe Pattern is a messaging or event system pattern where the message sender (publisher) does not directly send messages to specific receivers (subscribers). Instead, the published messages are categorized into a particular category without a defined recipient. Subscribers can express interest in one or more categories and only receive messages they are interested in. The publisher and subscriber usually have no direct relationship (low coupling).
The Publish-Subscribe pattern is the core concept behind implementing reactive streams, and it is the meaning expressed by the term “reactive.” We can understand it through a simple example model:
interface Subscriber {
void update(String message);
}
class Publisher {
private final List<Subscriber> subscribers = new ArrayList<>();
void subscribe(Subscriber subscriber) {
subscribers.add(subscriber);
}
void publish(String message) {
subscribers.forEach(subscriber -> subscriber.update(message));
}
}
class ConcreteSubscriber implements Subscriber {
private final String name;
ConcreteSubscriber(String name) {
this.name = name;
}
@Override
public void update(String message) {
System.out.println(name + " received: " + message);
}
}
public class Main {
public static void main(String[] args) {
Publisher publisher = new Publisher();
Subscriber bob = new ConcreteSubscriber("Bob");
Subscriber alice = new ConcreteSubscriber("Alice");
publisher.subscribe(bob);
publisher.subscribe(alice);
publisher.publish("Hello, World!");
}
}In reactive programming, this pattern is extended and improved to support asynchronous processing of data streams and backpressure management. In Reactive Streams specification and frameworks based on it (such as Reactor, RxJava, etc.), the Publisher (publisher) sends a data stream to the Subscriber (subscriber), while the Subscriber can control the rate at which it receives the data stream.
In Java 9, the official package java.util.concurrent (JUC) has encapsulated a simplified version of this reactive stream, highlighting the important role and value of reactive programming in concurrent programming.
Backpressure
Backpressure is a flow control mechanism and a method for handling the mismatch in data stream speeds in reactive systems. In reactive programming, the concept of backpressure is very important. Consider this scenario: when the publisher (Producer) produces data faster than the subscriber (Subscriber) can consume it, problems arise. Without a control mechanism, the subscriber may be overwhelmed by the large backlog of data (message backlog), which could lead to resource exhaustion (e.g., memory overflow) or performance degradation.
Backpressure mechanisms are designed to solve this issue. Under backpressure, the subscriber can control the rate at which it receives data to ensure it is not overwhelmed by the backlog. In the Reactive Streams specification, backpressure is implemented via the Subscription interface. The subscriber can use the Subscription.request(n) method to tell the publisher it can process n elements. When the subscriber is ready to handle more, it can call this method again. On the other hand, the subscriber can also use Subscription.cancel() to tell the publisher it no longer needs data and cancel the subscription.
We continue with the cafeteria example, using Reactor’s Flux class as a basis to implement backpressure. Suppose customers can eat 5 plates of scrambled eggs with tomatoes at a time, with a consumption speed of 500 milliseconds per plate, while the kitchen delivers scrambled eggs at a speed of 200 milliseconds per plate. This is a clear case where the publisher sends messages faster than the consumer can consume them, and backpressure is needed to control this:
public static void main(String[] args) {
Flux<String> foodFlux = Flux.interval(Duration.ofMillis(200)) // Serve a plate of scrambled eggs with tomatoes every 200 milliseconds
.map(i -> "Scrambled eggs with tomatoes" + i);
// Use BaseSubscriber to implement backpressure control
foodFlux.subscribe(new BaseSubscriber<>() {
int count = 0; // Track the number of scrambled eggs with tomatoes eaten
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println("Starting to queue for food");
request(1); // Take one plate of scrambled eggs with tomatoes at a time
}
@Override
protected void hookOnNext(String food) {
System.out.println("Chosen: " + food);
count++;
try {
Thread.sleep(500); // Assume it takes 500 milliseconds to eat each plate of scrambled eggs with tomatoes
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Eaten: " + food);
if (count >= 5) { // Assume the maximum is 5 plates of scrambled eggs with tomatoes
cancel();
} else {
request(1); // Continue to take the next plate of scrambled eggs with tomatoes
}
}
@Override
protected void hookOnCancel() {
System.out.println("Customer is full, ending the meal");
}
});
try {
Thread.sleep(5000); // Main thread waits for 5 seconds to observe the output
} catch (InterruptedException e) {
e.printStackTrace();
}
}If the reader has used MQ message queues (ActiveMQ, RabbitMQ, Kafka, RocketMQ, Pulsar, etc.), they will be very familiar with this process. In many cases, reactive programming and message queue systems share similar strategies for handling backpressure. MQ systems use a buffering mechanism, which is the message queue, to cache the data produced by the producer, while the consumer processes data from the queue at its own rate.
In addition, these systems often provide more fine-grained flow control mechanisms, such as batch fetching of messages or adjusting the consumer’s concurrency level, to better handle the rate mismatch problem. In reactive programming, similar functionalities can be implemented using operators provided by libraries like Reactor and RxJava.
However, despite their similarities, there are still significant differences in implementation details, use cases, design goals, and so on. Message queue systems are typically used to handle asynchronous message passing in distributed systems, while reactive programming is more focused on building efficient, event-driven programs.
Publisher
The publisher is the data producer, and in different frameworks, it is designed under different class names:
- Observable (RxJava) / Mono (Reactor): A publisher that can represent a 0-element sequence.
- Single (RxJava) / Mono (Reactor): A publisher that can represent a 1-element sequence.
- Observable (RxJava) / Flux (Reactor): A publisher that can represent a 0 to N-element sequence.
Various operators (such as map, filter, flatMap, etc.) can be used when operating on these sequences. These asynchronous, non-blocking operators allow for complex operations on the sequence. For example, in Reactor:
// Use Flux to publish a random number between 0 and 100
Flux<Integer> flux = Flux.range(0, 100)
// Expand the elements in Flux by two times
.map(i -> i * 2)
// Subscribe to the output task to print the results
.subscribe(System.out::println);
// Publishing a string with Mono
Mono.just("Hello, World!")
// Subscribe to the output task to print the results
.subscribe(System.out::println);Subscriber
In reactive programming, the subscriber is the consumer of the data stream. The subscriber subscribes to the publisher (Publisher) to receive the data stream and processes the received data. The subscriber needs to implement the Subscriber interface defined in the Reactive Streams specification, which includes four methods: onSubscribe(Subscription), onNext(T), onError(Throwable), and onComplete(). These methods are called when the subscription begins, when data is received, when an error occurs, and when the processing is completed, respectively.
Scheduler
A scheduler is used to control on which thread the data stream processing and publishing are executed. In reactive programming libraries like Reactor and RxJava, various schedulers are provided, such as Schedulers.parallel() for parallel processing and Schedulers.single() for single-threaded processing. By using different schedulers, you can schedule the processing tasks on different threads or thread pools, enabling asynchronous, concurrent, or parallel processing.
For example, the following code creates a Flux and specifies that the data will be generated on an asynchronous thread and processed on the main thread:
public class SchedulerExample {
public static void main(String[] args) {
Flux<Integer> flux = Flux.range(1, 5)
.publishOn(Schedulers.boundedElastic()) // Scheduler for asynchronous
.map(i -> {
System.out.println("Publish " + i + " in " + Thread.currentThread().getName());
return i * i;
})
.subscribeOn(Schedulers.parallel()) // Scheduler for parallel processing
.doOnNext(i -> System.out.println("Handle " + i + " in " + Thread.currentThread().getName()));
flux.subscribe();
}
}In this example, .publishOn(Schedulers.boundedElastic()) schedules the task of generating data to a thread for asynchronous processing, and .subscribeOn(Schedulers.parallel()) schedules the task of processing data to a thread for parallel processing.
Reference
[1] 长发 & 旭孟 & 向鹏. (2022.5). CompletableFuture原理与实践-外卖商家端API的异步化. Retrieved from https://tech.meituan.com/2022/05/12/principles-and-practices-of-completablefuture.html
[2] Grzegorz Piwowarek. (2019.7). CompletableFuture – The Difference Between thenApply/thenApplyAsync.Retrieved from https://4comprehension.com/completablefuture-the-difference-between-thenapply-thenapplyasync/
[3] Martin Buchholz & David Holmes. (2015.3). Rare lost unpark when very first LockSupport.park triggers class loading. Retrieved from https://bugs.openjdk.org/browse/JDK-8074773
[4] 方腾飞 & 魏鹏 & 程晓明. (2015). Java并发编程的艺术. 机械工业出版社. (Original work published 2015)
[5] Defog Tech. (2018.1). Introduction to CompletableFuture in Java 8. Retrieved from https://www.youtube.com/watch?v=ImtZgX1nmr8
[6] Spring Official. (2023.5). Spring Framework WebFlux Overview. Retrieved from https://docs.spring.io/spring-framework/reference/web/webflux/new-framework.html