
Abstract
The first rule in the Songshan Edition of Alibaba’s Java Development Manual regarding logging explicitly states that: applications should not directly use the APIs of logging systems (Log4j, Logback), but instead, should rely on the APIs of logging frameworks (SLF4J, JCL—Jakarta Commons Logging), using the facade pattern for logging framework development.
As Apache once said: “Troubleshooting any issue without error logs is like driving with your eyes closed,” highlighting the importance of logs. In daily development, logging is an essential step because logs are crucial for troubleshooting and application monitoring. In modern application development, logging is typically implemented through SLF4J. Using the logging facade pattern not only helps standardize the logging method but also makes it easier to switch logging frameworks in the future.

Common Usage
For example, with SLF4J, developers typically use two methods for logging in daily development:
private static final Logger LOGGER = LoggerFactory.getLogger(LoggerTest.class);
@Test
public void LoggerTestUnit() {
log.info("successfully loaded {} beans", 3); // @SLF4J
LOGGER.info("successfully loaded {} beans", beanContainer.size()); // Logger Factory
}However, in many cases, this Logger method will be encapsulated again in the framework development of the enterprise, and the final form may be as follows:
LoggerUtil.info(LOGGER, "print: {}", "this is the log");Problem Emergence
Many people feel that since SLF4J is already a logging facade and well encapsulated, there is no need to add another layer of abstraction by creating a LoggerUtil to output logs. However, this is also explained in the development guidelines:
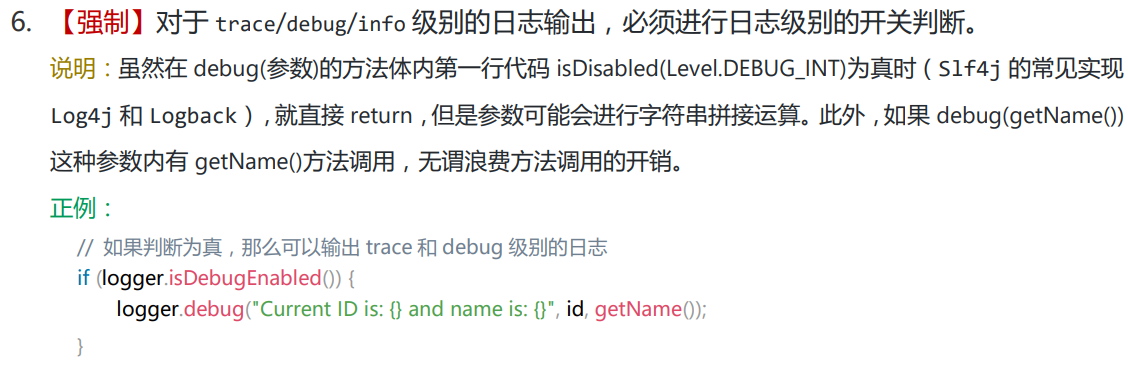
The meaning of this passage, when translated simply, is: Regardless of whether a log level is enabled or not, the method will first process the parameters (which is caused by Java itself), and then enter the Logger to check whether the log level is enabled to decide whether to output the log.
When these parameters contain complex methods like JSON.toJSONString(error), for example, these methods are executed first before being passed to the Logger for output. Below is a simulated case:
@Test
public void LoggerTestUnit() {
long startTime = System.currentTimeMillis();
LOGGER.info("info {}", mockComplexMsgProcess(new Object()));
System.out.println("this execution spends " + (System.currentTimeMillis() - startTime) + " ms");
}
public String mockComplexMsgProcess(Object infomation) {
if (infomation == null) {
throw new NullPointerException("information can't be null");
}
// Here we simulate a very complex method of
// processing objects in info. This process takes 3 seconds.
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return infomation.toString();
}In the test results, this method took 3002ms. Although it was just outputting log information, a large amount of time was spent during the mockComplexMsgProcess phase. This type of log printing can have a significant impact on high-concurrency scenarios such as flash sales or peak events. When a service receives a large volume of requests, it will also generate massive log I/O operations, which can have an incalculable effect on the server’s performance.
Attempt to Solve the Problem
Completely disabling logs may not be a good solution because logs provide important information about the system’s operation. For diagnosing issues, especially during critical moments like flash sales, this information can be crucial. Therefore, some feasible solutions involve adjusting the logging strategy, such as:
- Adjust the log level: You can change the log level to error or warning, recording only key information.
- Asynchronous logging: You can write logs asynchronously to reduce the impact of log writing on the main program.
- Log sampling: For certain types of logs, you can choose to sample a subset rather than recording everything.
- Use a dedicated logging service: For example, using log collection tools like Fluentd or Logstash to send logs to services like ElasticSearch, CloudWatch Logs, etc., for analysis.
- Efficient log formats: Using structured log formats (such as JSON) facilitates subsequent processing and analysis, and can also reduce the log size.
- Use distributed tracing systems: In a microservice architecture, distributed tracing systems like Jaeger or Zipkin can help trace specific requests among massive requests, aiding in problem identification.
- Disk I/O and Network I/O: If your logging system supports it, consider writing logs to a low-priority I/O queue or using a separate network connection to send logs, reducing the impact on the main program.
Here, we focus on the first method. Using slf4j-simple as an example, you can raise the log level to error in high-concurrency environments (e.g., System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "error");). This will selectively output only important error-type logs:
private static final Logger LOGGER = LoggerFactory.getLogger(LoggerTest.class);
@Test
public void loggerTest() {
// Increase the log level
System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "error");
long startTime = System.currentTimeMillis();
LOGGER.debug("{}", mockSlowArgument("Arena", "testing"));
System.out.println("this logger cost " + (System.currentTimeMillis() - startTime) + " ms");
}
public String mockSlowArgument(String name, String info) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return name + "-" + info;
}If you analyze the above code carefully, you will easily find that this does not solve the latency problem, but simply reduces the log I/O overhead. However, you can add the following log level judgment to pre-process whether these logs need to be called:
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("{}", mockSlowArgument("Dioxide_CN", "testing"));
}To avoid the need for repetitive if checks, developers often encapsulate the if conditions into utility classes, which is what the LogUtils tool mentioned at the beginning of the article aims to achieve. However, this approach only avoids the if check when printing “existing parameters” and does not affect the parameters of “method types.” Therefore, this cannot serve as the final LogUtils for use in development. As developers, we should consider a way to lazily load (deferred loading) the parameters.
Functional Interfaces and Lazy Chains
Supplier, a functional interface that provides a way to get a result, is the perfect choice for deferred loading methods. We can delegate the mockSlowArgument method from earlier to the Supplier interface and add checks to see if the log level is enabled, achieving a more precise lazy-loaded log tool encapsulation. Here is a simple example:
public class LoggerTest {
@Test
public void lazyLoggerTest() {
System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "error");
long startTime = System.currentTimeMillis();
// This statement will be blocked by the log level judgment
LogUtils.info(LoggerTest.class, "Hello! {} this is INFO", () -> mockSlowArgument("Dioxide", "CN"));
// This statement will be called
LogUtils.error(LoggerTest.class, "Hello! {} this is ERROR", () -> mockSlowArgument("Dioxide", "CN"));
System.out.println("this logger cost " + (System.currentTimeMillis() - startTime) + " ms");
}
public String mockSlowArgument(String name, String info) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return name + "-" + info;
}
}
/**
* Encapsulate LogUtils to implement
* delayed loading and log level judgment
*/
class LogUtils {
private LogUtils() {}
public static void info(Class<?> clazz, String message, Supplier<?>... suppliers) {
log(Level.INFO, clazz, message, suppliers);
}
public static void debug(Class<?> clazz, String message, Supplier<?>... suppliers) {
log(Level.DEBUG, clazz, message, suppliers);
}
public static void warn(Class<?> clazz, String message, Supplier<?>... suppliers) {
log(Level.WARN, clazz, message, suppliers);
}
public static void error(Class<?> clazz, String message, Supplier<?>... suppliers) {
log(Level.ERROR, clazz, message, suppliers);
}
public static void trace(Class<?> clazz, String message, Supplier<?>... suppliers) {
log(Level.TRACE, clazz, message, suppliers);
}
private static void log(Level level, Class<?> clazz, String message, Supplier<?>... suppliers) {
Logger logger = LoggerFactory.getLogger(clazz);
// 判断日志级别是否被启用
switch (level) {
case DEBUG -> {
if (logger.isDebugEnabled()) {
logger.debug(message, getLogArgs(suppliers));
}
}
case INFO -> {
if (logger.isInfoEnabled()) {
logger.info(message, getLogArgs(suppliers));
}
}
case ERROR -> {
if (logger.isErrorEnabled()) {
logger.error(message, getLogArgs(suppliers));
}
}
case WARN -> {
if (logger.isWarnEnabled()) {
logger.warn(message, getLogArgs(suppliers));
}
}
case TRACE -> {
if (logger.isTraceEnabled()) {
logger.trace(message, getLogArgs(suppliers));
}
}
default ->
throw new IllegalArgumentException("Unexpected Level: " + level);
}
}
private static Object[] getLogArgs(Supplier<?>... suppliers) {
if (suppliers == null || suppliers.length == 0) {
return new Object[]{};
} else {
return Arrays.stream(suppliers).map(Supplier::get).toArray();
}
}
}After a series of encapsulations, a simple LogUtils was successfully implemented. Since the error log level is enabled, only logs at the error level are output. Unsurprisingly, the method execution time is around milliseconds, not milliseconds.
SLF4J 2.0
The implementation principle mentioned above is also reflected in the util.Logger interface encapsulated in log4j-api-2.17.2. However, the SLF4J log facade does not support Supplier, and readers can refer to the source code for detailed implementation.
So why doesn’t SLF4J support it? This has been discussed, and you can see the discussion in the Add jdk 1.8 support by ouertani · Pull Request #70 · qos-ch/slf4j (github.com) issue. The main points are not repeated here. The final result is that SLF4J-2.0 supports the Fluent Logging API syntax, which is used as follows:
@Test
public void loggerTest() {
System.setProperty("org.slf4j.simpleLogger.defaultLogLevel", "error");
Logger LOGGER = LoggerFactory.getLogger(LoggerTest.class);
long startTime = System.currentTimeMillis();
LOGGER
.atInfo()
.setMessage("{}")
.addArgument(() -> mockSlowArgument("Arena", "testing"))
.log();
LOGGER
.atError()
.setMessage("{}")
.addArgument(() -> mockSlowArgument("Arena", "testing"))
.log();
System.out.println("this logger cost " + (System.currentTimeMillis() - startTime) + " ms");
}The final result still fluctuates around milliseconds and only outputs error-level logs. It’s important to note that SLF4J’s Fluent API depends on the specific implementation of the Logger (e.g., Logback or Log4j). Specific log operations, such as message formatting, parameter replacement, etc., are still handled by the Logger’s implementation.
When adjusting logging strategies or encapsulating logging tools, developers need to balance the demands of “performance” and “observability,” which may require some testing and adjustments in real environments.
Reference
[1] SLF4J. (n.d.). SLF4J Manual - Fluent Logging API. https://www.slf4j.org/manual.html#fluent
[2] QOS.CH. (n.d.). SLF4J. https://github.com/qos-ch/slf4j
[3] Alibaba. (2020, August 3). Songshan Edition of Alibaba’s Java Development Manual.